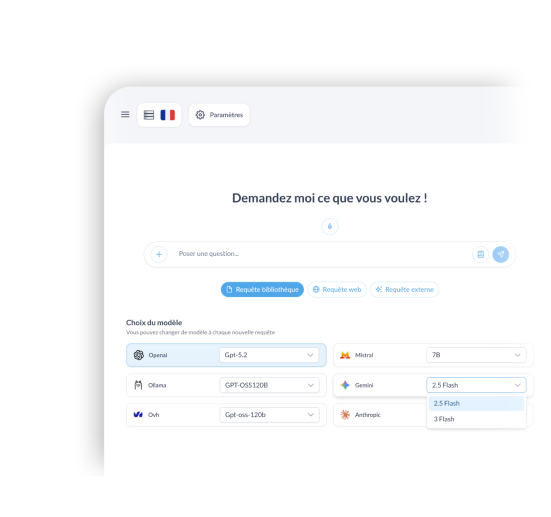
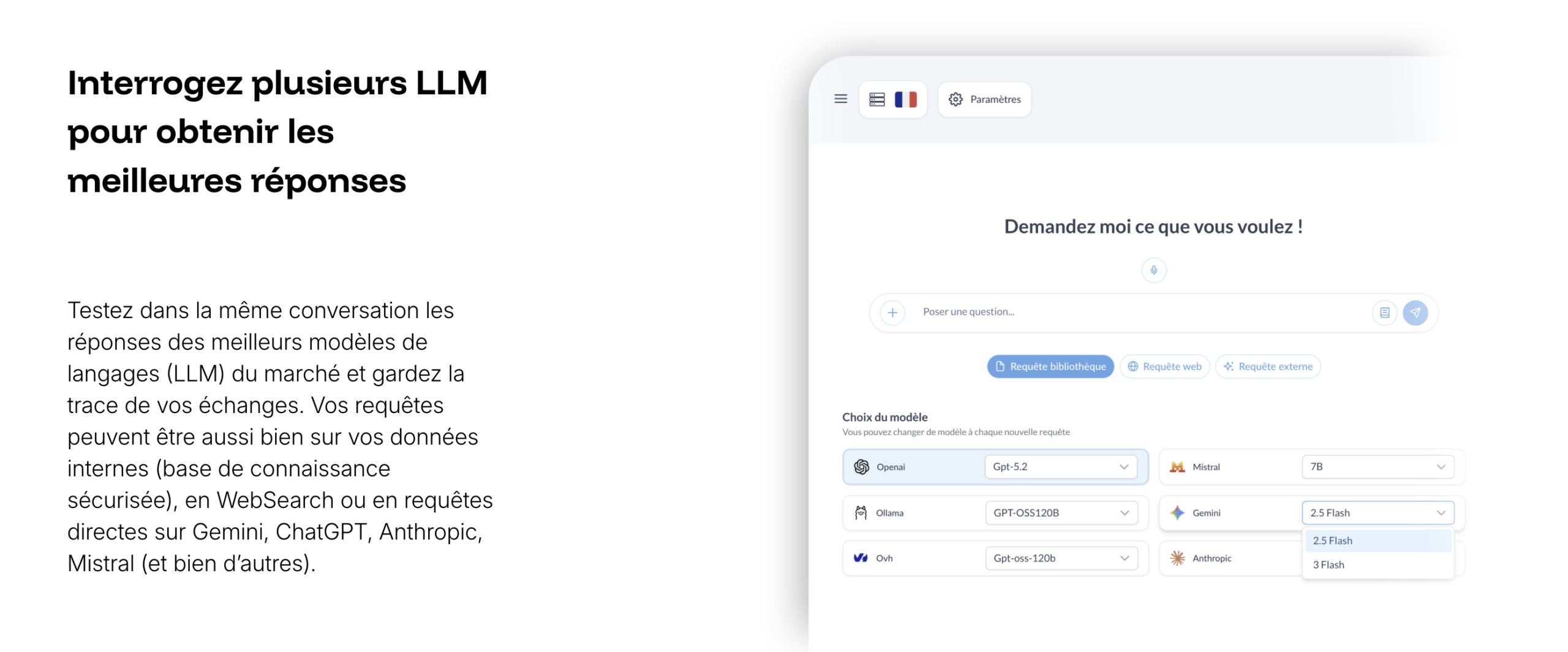
Query multiple LLMs to get the best answers
Launch the same question on multiple models in parallel, compare the answers side by side, then keep the most reliable, clearest, or best-formulated response.
Compare answers without switching tools
Test multiple AI models in parallel and compare their answers side by side.
Your queries can rely on your knowledge base, the web, or external models (ChatGPT, Gemini, Anthropic, Mistral, etc.).
Keep the best answer and reuse it immediately in your content.
All in one place,
without juggling 5 subscriptions.
Compare multiple AIs without losing 30 minutes
One query → multiple models → multiple answers.
You keep the best one.
Without Multi-LLM
- Copy/paste the same request
- Open 3 different LLMs
- Lose track of versions
With Multi-LLM
- One single query
- Multiple answers in the same place
- Immediate comparison
Test on a real request
Launch the same query on multiple models, then keep the most useful answer.
Check consistency
Same question, multiple models: quickly spot what differs before relying on an answer.
“Explain X simply, with 3 points to check.”
Check reliability
Same question, multiple models: quickly spot what differs before relying on an answer.
“Explain X simply, with 3 points to check.”
Check quality
Same question, multiple models: quickly spot what differs before relying on an answer.
“Explain X simply, with 3 points to check.”
Videos
Multi-LLM helps you properly separate scopes without multiplying accounts.
Decide faster, with more perspective
Multi-LLM helps you compare, verify, and choose without multiplying tools.

Reliability
Spot contradictions
Consistency
Compare multiple answers
Efficiency
Save time and effort
Our other features
WordPress Addon
ChatWeb html
Fullscreen ChatBot
Your frequently asked questions
This section is only for SEO purposes; otherwise, you could simply ask your questions to our ChatBot linked to the knowledge base of our solution…
Les usages de narratheque sont quasiment infinis. Si vous souhaitez proposer une collaboration sur un secteur d’activité ou auprès de votre communauté n’hésitez pas à nous solliciter.
Nous ne proposons pas pour le moment de version en marque blanche à proprement parlé, nous étudierons toutes les demandes en fonction des opportunités.
En fonction du territoire que vous avez choisi (pour le moment Europe ou Canada), vos données sont stockées sur des serveurs dédiés et sécurisés. Vos données sont privées et ne serviront jamais à entrainer un quelconque modèle.
Un RAG (Retrieval-Augmented Generation) est une technique d’intelligence artificielle qui permet à un modèle de langage de chercher des informations dans une base de connaissances avant de répondre. C’est exactement ce que fait narratheque, de manière extrêmement simple et rapide.
Pour le moment chaque Base de Connaissances est limitée par défaut à 100 Go de stockage. L’import de fichiers est limité à 1Go par fichier. Si besoin, cette limite peut être ajustée en fonction de vos besoins spécifiques.
La liste des modèles de langages disponibles dans narratheque.io évolue régulièrement, en fonction de leurs mises à jour. Et chaque LLM est souvent déclinée en plusieurs versions pour s’adapter à vos besoins. Les plus courant sont les modèles d’OpenAi, de Google, d’Anthropic, de Mistral et de Ollama. N’hésitez pas à consulter la page qui y est consacrée.
Do you have specific needs? Let’s discuss your project.
narratheque.io is the public version of the KDBCore application core by Jolifish Europe. It allows the creation of dedicated environments to meet specific needs and dedicated connection or hosting constraints. Do not hesitate to make an appointment to present your project to us.